How do you impute missing values in R?
- colsum(is.na(data frame))
- sum(is.na(data frame$column name)
- Missing values can be treated using following methods :
- Mean/ Mode/ Median Imputation: Imputation is a method to fill in the missing values with estimated ones.
- Prediction Model: Prediction model is one of the sophisticated method for handling missing data.
Thereof, can Knn handle categorical data?
KNN is an algorithm that is useful for matching a point with its closest k neighbors in a multi-dimensional space. It can be used for data that are continuous, discrete, ordinal and categorical which makes it particularly useful for dealing with all kind of missing data.
Similarly, how do you fill missing values in a data set? Fill-in or impute the missing values. Use the rest of the data to predict the missing values. Simply replacing the missing value of a predictor with the average value of that predictor is one easy method.
Similarly, how do you impute missing values?
The following are common methods:
- Mean imputation. Simply calculate the mean of the observed values for that variable for all individuals who are non-missing.
- Substitution.
- Hot deck imputation.
- Cold deck imputation.
- Regression imputation.
- Stochastic regression imputation.
- Interpolation and extrapolation.
How do you deal with missing values in linear regression?
Simple approaches include taking the average of the column and use that value, or if there is a heavy skew the median might be better. A better approach, you can perform regression or nearest neighbor imputation on the column to predict the missing values. Then continue on with your analysis/model.
Related Question Answers
How do you do multiple imputation in R?
These 5 steps are (courtesy of this website): impute the missing values by using an appropriate model which incorporates random variation. repeat the first step 3-5 times. perform the desired analysis on each data set by using standard, complete data methods.How do you impute missing values for categorical variables?
There is various ways to handle missing values of categorical ways.- Ignore observations of missing values if we are dealing with large data sets and less number of records has missing values.
- Ignore variable, if it is not significant.
- Develop model to predict missing values.
- Treat missing data as just another category.
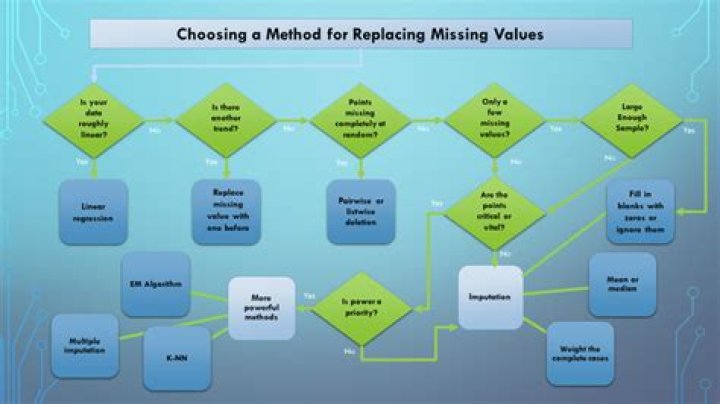
How do we choose best method to impute missing value for a data?
Choosing best method to impute the missing values of data is based on applying trial and error .- First we need to create a subset of data from the population.
- Then delete some of the values manually.
- Impute those deleted values with Imputation methods which are mentioned above.
What is KNN imputation?
The k nearest neighbors algorithm can be used for imputing missing data by finding the k closest neighbors to the observation with missing data and then imputing them based on the the non-missing values in the neighbors.What do you do with missing values in R?
When you import dataset from other statistical applications the missing values might be coded with a number, for example 99 . In order to let R know that is a missing value you need to recode it. Another useful function in R to deal with missing values is na. omit() which delete incomplete observations.How do you impute data in R?
Dealing with Missing Data using R- colsum(is.na(data frame))
- sum(is.na(data frame$column name)
- Missing values can be treated using following methods :
- Mean/ Mode/ Median Imputation: Imputation is a method to fill in the missing values with estimated ones.
- Prediction Model: Prediction model is one of the sophisticated method for handling missing data.
How does mice work in R?
MICE (Multivariate Imputation via Chained Equations) is one of the commonly used package by R users. Creating multiple imputations as compared to a single imputation (such as mean) takes care of uncertainty in missing values. By default, linear regression is used to predict continuous missing values.How do I ignore missing values in R?
An shorthand alternative is to simply use na. omit() to omit all rows containing missing values.Which can be substituted in place of a missing value?
One of the most widely used imputation methods in such a case is the last observation carried forward (LOCF). This method replaces every missing value with the last observed value from the same subject. Whenever a value is missing, it is replaced with the last observed value [12].How do you handle missing categorical data in R?
There is various ways to handle missing values of categorical ways.- Ignore observations of missing values if we are dealing with large data sets and less number of records has missing values.
- Ignore variable, if it is not significant.
- Develop model to predict missing values.
- Treat missing data as just another category.
How do you use the Replace function in R?
replace- Replace Values in a Vector. replace replaces the values in x with indices given in list by those given in values .
- Usage. replace(x, list, values)
- Arguments. x.
- Value. A vector with the values replaced.
- Note. x is unchanged: remember to assign the result.
- References.
- Aliases.
What does na mean in R?
not availableHow do you calculate mean in R?
Mean. It is calculated by taking the sum of the values and dividing with the number of values in a data series. The function mean() is used to calculate this in R.How do you find the distance between categorical variables?
3 Answers- Assign numeric value to each property so the order matches the meaning behind the property if possible.
- For each concept find scale factor and offset so all property values fall in the same chosen range, say [0-100] Sx = 100 / (Px max - Px min) Ox = -Px min.
How does KNN algorithm work?
KNN works by finding the distances between a query and all the examples in the data, selecting the specified number examples (K) closest to the query, then votes for the most frequent label (in the case of classification) or averages the labels (in the case of regression).What is Knn regression?
Algorithm. A simple implementation of KNN regression is to calculate the average of the numerical target of the K nearest neighbors. Another approach uses an inverse distance weighted average of the K nearest neighbors. KNN regression uses the same distance functions as KNN classification.Can you use categorical variables in SVM?
Among the three classification methods, only Kernel Density Classification can handle the categorical variables in theory, while kNN and SVM are unable to be applied directly since they are based on the Euclidean distances. Finally, the introduction of dummy variables usually increase the dimension significantly.What is K value in Knn?
'k' in KNN is a parameter that refers to the number of nearest neighbours to include in the majority of the voting process. Let's say k = 5 and the new data point is classified by the majority of votes from its five neighbours and the new point would be classified as red since four out of five neighbours are red.How does Python implement Knn?
kNN Algorithm Manual Implementation- Step1: Calculate the Euclidean distance between the new point and the existing points.
- Step 2: Choose the value of K and select K neighbors closet to the new point.
- Step 3: Count the votes of all the K neighbors / Predicting Values.




