Does Perceptron use gradient descent?
Accordingly, which algorithms use gradient descent?
Common examples of algorithms with coefficients that can be optimized using gradient descent are Linear Regression and Logistic Regression.
Similarly, which learning rule uses gradient descent? Another way to explain the Delta rule is that it uses an error function to perform gradient descent learning. A tutorial on the Delta rule explains that essentially in comparing an actual output with a targeted output, the technology tries to find a match. If there is not a match, the program makes changes.
Likewise, what is a Perceptron explain the gradient descent method for Perceptron learning?
Gradient descent is a search strategy used in continuous search spaces. It is the basis for the error backpropagation algorithm used to train multilayer artificial neural networks. Below I explain how gradient descent works in general and how it applies in particular to training a single layer perceptron network.
Do neural networks use gradient descent?
The most used algorithm to train neural networks is gradient descent. We'll define it later, but for now hold on to the following idea: the gradient is a numeric calculation allowing us to know how to adjust the parameters of a network in such a way that its output deviation is minimized.
Related Question Answers
Is SGD better than Adam?
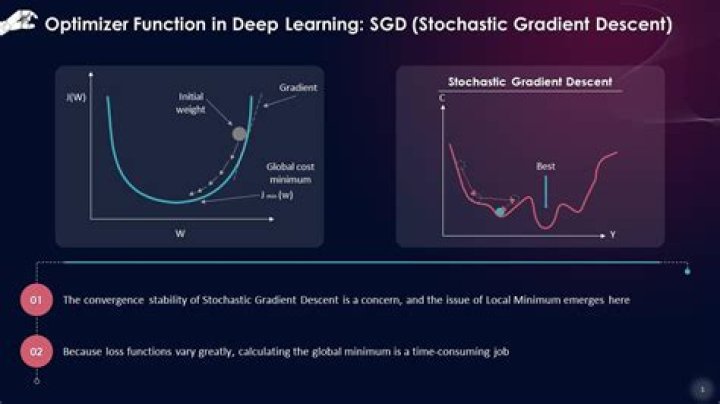
Adam is great, it's much faster than SGD, the default hyperparameters usually works fine, but it has its own pitfall too. Many accused Adam has convergence problems that often SGD + momentum can converge better with longer training time. We often see a lot of papers in 2018 and 2019 were still using SGD.Why is gradient descent used?
Gradient Descent is an optimization algorithm for finding a local minimum of a differentiable function. Gradient descent is simply used in machine learning to find the values of a function's parameters (coefficients) that minimize a cost function as far as possible.Why does Adam converge faster than SGD?
So SGD is more locally unstable than ADAM at sharp minima defined as the minima whose local basins have small Radon measure, and can better escape from them to flatter ones with larger Radon measure. These algorithms, especially for ADAM, have achieved much faster convergence speed than vanilla SGD in practice.Is Adam stochastic gradient descent?
Adam is a replacement optimization algorithm for stochastic gradient descent for training deep learning models. Adam combines the best properties of the AdaGrad and RMSProp algorithms to provide an optimization algorithm that can handle sparse gradients on noisy problems.What is SGD machine learning?
Stochastic Gradient Descent (SGD) is a simple yet very efficient approach to fitting linear classifiers and regressors under convex loss functions such as (linear) Support Vector Machines and Logistic Regression. The advantages of Stochastic Gradient Descent are: Efficiency.Is gradient descent used in linear regression?
Gradient Descent Algorithm gives optimum values of m and c of the linear regression equation. With these values of m and c, we will get the equation of the best-fit line and ready to make predictions. Understanding The Practical Applications of Linear Regression Models!What is gradient descent and delta rule?
Gradient descent is a way to find a minimum in a high-dimensional space. You go in direction of the steepest descent. The delta rule is an update rule for single layer perceptrons. It makes use of gradient descent.Can perceptron implement XOR?
A "single-layer" perceptron can't implement XOR. The reason is because the classes in XOR are not linearly separable. You cannot draw a straight line to separate the points (0,0),(1,1) from the points (0,1),(1,0).How does perceptron algorithm work?
A perceptron has one or more than one inputs, a process, and only one output. A linear classifier that the perceptron is categorized as is a classification algorithm, which relies on a linear predictor function to make predictions. Its predictions are based on a combination that includes weights and feature vector.What is the objective of perceptron learning?
Explanation: The objective of perceptron learning is to adjust weight along with class identification.Why do we need gradient descent and delta rule for neural networks training?
The key idea behind the delta rule is to use gradient descent to search the hypothesis space of possible weight vectors to find the search the hypothesis space of possible weight vectors to find the weights that best fit the training data.What is a perceptron learning rule?
Perceptron Learning Rule states that the algorithm would automatically learn the optimal weight coefficients. The input features are then multiplied with these weights to determine if a neuron fires or not. In the context of supervised learning and classification, this can then be used to predict the class of a sample.What are weights in perceptron?
So the weights are just scalar values that you multiple each input by before adding them and applying the nonlinear activation function i.e. w1 and w2 in the image. So putting it all together, if we have inputs x1 and x2 which produce a known output y then a perceptron using activation function A can be written as.What is the perceptron cost function?
The Perceptron cost functionis a point when the dimension of the input is N=1 (as we saw in e.g., Example 2 of the previous Section), a line when N=2 (as we saw in e.g, Example 3 of the previous Section), and is more generally for arbitray N a hyperplane defined in the input space of a dataset.
Is logistic regression A perceptron?
Logistic regression and the perceptron algorithm are very similar to each other. It's common to think of logistic regression as a kind of perceptron algorithm on steroids, in that a logistic model can predict probabilities while a perceptron can only predict yes or no.Which activation function Cannot be used for gradient descent?
Hence, Threshold activation function cannot be used in Gradient Descent learning. Whereas a Linear Activation function (or any other function that is differential) allows the derivative of the error to be calculated.What is the role of gradient descent in deep learning using neural network design?
tl;dr Gradient Descent is an optimization technique that is used to improve deep learning and neural network-based models by minimizing the cost function.What does lower learning rate in gradient descent lead to?
A smaller learning rate may allow the model to learn a more optimal or even globally optimal set of weights but may take significantly longer to train. When the learning rate is too large, gradient descent can inadvertently increase rather than decrease the training error.Why do we use gradient descent in linear regression?
The main reason why gradient descent is used for linear regression is the computational complexity: it's computationally cheaper (faster) to find the solution using the gradient descent in some cases. Here, you need to calculate the matrix X′X then invert it (see note below). It's an expensive calculation.What is the delta rule used in Ann?
The delta rule in an artificial neural network is a specific kind of backpropagation that assists in refining the machine learning/artificial intelligence network, making associations among input and outputs with different layers of artificial neurons. The Delta rule is also called the Delta learning rule.What is learning rate in gradient descent?
Deep learning neural networks are trained using the stochastic gradient descent optimization algorithm. The learning rate is a hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated.How does gradient descent work?
Gradient descent is an iterative optimization algorithm for finding the local minimum of a function. To find the local minimum of a function using gradient descent, we must take steps proportional to the negative of the gradient (move away from the gradient) of the function at the current point.How do you use gradient descent in Python?
What is Gradient Descent?- Choose an initial random value of w.
- Choose the number of maximum iterations T.
- Choose a value for the learning rate η∈[a,b]
- Repeat following two steps until f does not change or iterations exceed T. a.Compute: Δw=−η∇wf(w) b. update w as: wâ†w+Δw.
How do you derive the gradient descent?
In simple words, we can summarize the gradient descent learning as follows:- Initialize the weights to 0 or small random numbers.
- For k epochs (passes over the training set) For each training sample. Compute the predicted output value. Compare to the actual output and Compute the “weight update†value.